TL;DR
Transformers, unveiled by Google in 2017, let AI models (GPTs) predict the next word with “self-attention.” OpenAI’s GPT-3/4 scaled the idea, powering ChatGPT. Trained on trillions of tokens, they draft text, code, images—but still hallucinate and guzzle energy. Expect agentic assistants and rising productivity, alongside real risks: misinformation, bias, job shifts, climate cost, and the march toward AGI.
Introduction
Human hunger for knowledge, innovation, and I guess easier lifestyle is ever present. From the flow of goods and services around the world (following industrial revolutions in the late 18th to mid 19th century) to transfer of ideas (following interconnectedness of the world through internet), global trade and ideas now move orders-of-magnitude faster than a century ago. Currently, as we reach the point where Moore’s Law limits how much faster our technological processing capacity, we have discovered another potential through Generative AIs or Large Language Models (LLMs) or more commonly known as GPTs.
What are these GPTs about?
GPT stands for Generative Pre-trained Transformer. GPT is a type of transformer. Transformer was introduced by researchers at Google in 2017 with an explanatory title “Attention is all you need.” It is a neural network that uses self-attention – a mechanism that allows understanding of dependencies and relationships within input sequences. Transformer refers to a broader architecture that includes encoder-only, decoder-only and encoder-decoder variants. Encoders allow reading the input in both direction (left to right and left to right) while decoder processes tokens one by one from left to right and produces output by asking “Given everything I’ve seen so far, what should come next?”
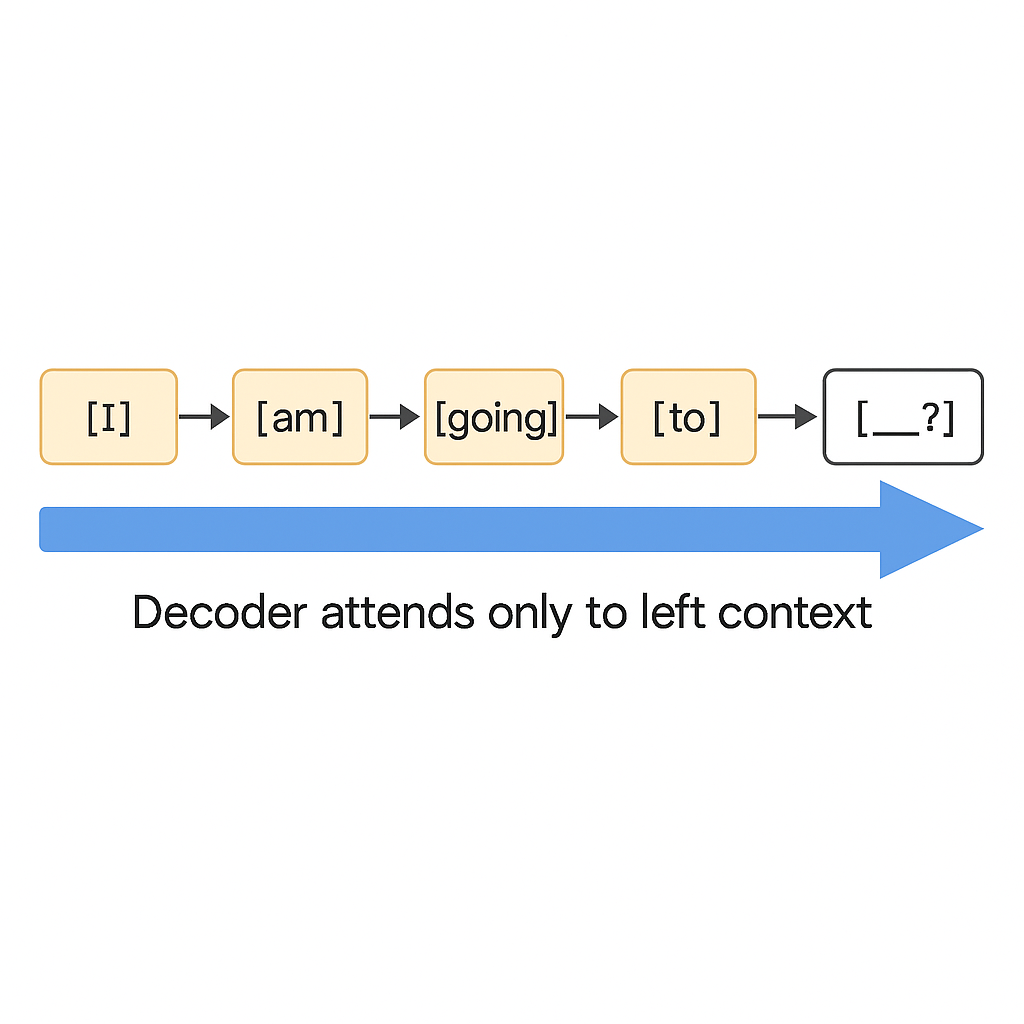
Imagine each word is a token:
On each step, decoder uses only what’s to the left to decide what comes next.
GPT, with decoder only integration, is able to produce output one word/token at a time based on the preceding context. Many prominent figures including Geoffrey Hinton have described this feature of GPT as autocomplete on steroids.
While GPT, as a name, is perhaps the most popular transformer variant so far, there are other variants of it that work under the hood of the algorithms of many top companies. Transformer architecture based models like mT5, PaLM2, NLLB-200, mBART etc. are used throughout major technology companies to perform most of the machine translations. We also have CLIP from OpenAI and DALL-E for OpenAI that also incorporate various forms of transformers.
OpenAI, a company founded in 2015, had no initial plan to adapt Transformers because they didn’t exist yet. They were looking into Reinforcement Learning (RL), robotics, and general-purpose AI safety only. In June 2017, Transformer architecture was unveiled through a scientific paper. OpenAI quickly adopted transformers. It released the first version of GPT called GPT-1 in 2018. By 2020, GPT-3 had been released. With further minor improvements and fixes, GPT-3.5 powered ChatGPT got released to the world. It went on to become the world’s fastest downloaded or accessed app within months.
If you had told anyone about a bot that can talk back to you like humans – except some tech bros and sis – until Midnight November 30, 2022, they would have been more likely called you crazy then reasonable.
In short, Google researchers invented the engine (Transformer) and OpenAI build the rocket ship (GPT) and scaled it beyond its initial utility. Now we have various open source and proprietary models from companies like Facebook, Anthropic, Deepseek etc. joining this revolution.
What makes these GPTs powerful is the massive scale and diversity of their training data. Modern models learn from trillions of tokens – equivalent to millions of books worth of text, plus images, code, and other data formats. This multimodal training allows today’s leading GPT models to analyze images, write code, and understand charts, not just generate text.
However, as we approach the limits of available high-quality data, the industry is moving towards synthetic data generation – using AI models to create training material for future models. Beyond their initial pretraining, these models require extensive fine-tuning through techniques like Reinforcement Learning from Human Feedback (RLHF) to align with human preferences and safety requirements.
Despite all the advancements we have in GPT so far, accuracy remains imperfect. Because GPTs predict the most statistically likely next token, they can generate convincing but inaccurate information – a phenomenon called “hallucination.” Also, the computational cost is enormous, with training runs costing tens of millions of dollars and consuming massive amounts of energy.
How do you access them?
It is easy, just get on a site like chatgpt.com and ask the same question.
A Brief History
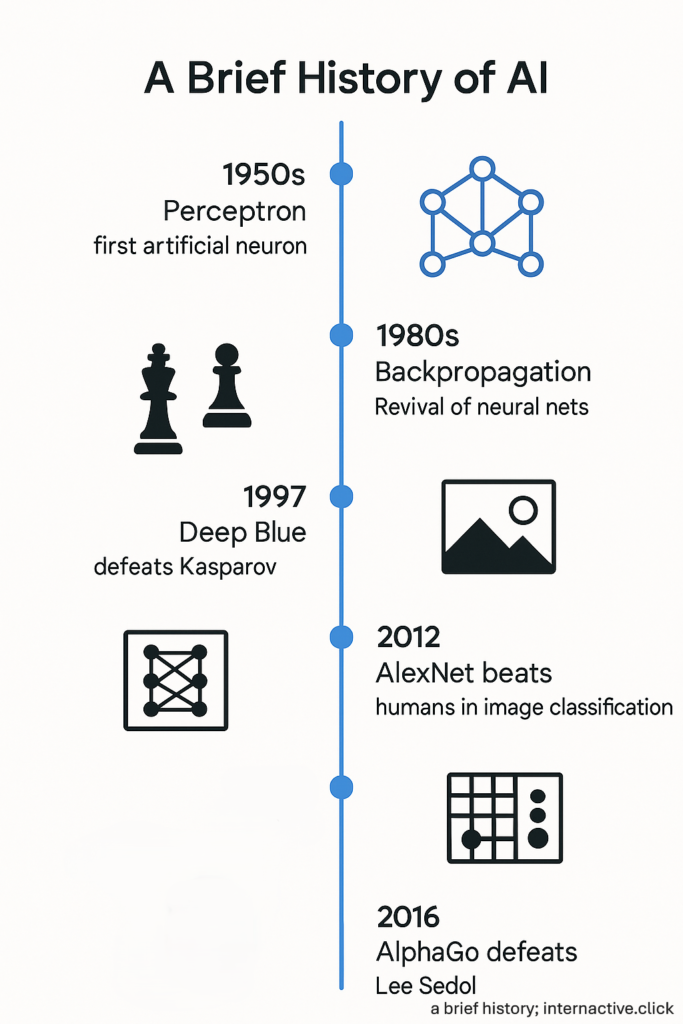
It started simple, with a perceptron, the first attempt to mimic a brain cell in silicon. Born in the 1950s, it fizzled out quickly – too simple to solve real problems. Artificial Intelligence was a hot topic around this period. Computer scientists turned to the biological brain and its mechanisms for inspiration.
Followed by failure in various attempts, Artificial Intelligence hype was slowly dying. In the 1980s, researchers revived the field with backpropagation, the algorithm that lets networks learn by trial and error. This gave rise to connectionism – the idea that intelligence could emerge from layered, interconnected units, much like neurons.
Still the progress was slow. Then, a computer beat the world chess champion. In 1997, IBM’s Deep Blue defeated Garry Kasparov. There was not much depth to Deep Blue, as it was just a supercharged calculator that used rule-based, brute-force search and handcrafted evaluation functions. But the feat was real, and it reignited interest in the field.
In 2006, Geoff Hinton and colleagues showed that deep neural networks – if trained properly using layer-wise pretraining – could tackle previously unsolvable problems. Fast forward to 2012, a convolutional neural network (CNN) architecture called AlexNet, built by Hinton’s student Alex Krizhevsky, shattered benchmarks in the ImageNet competition. AlexNet, for the first time in human history, beat humans at image classification tasks. This marked the true beginning of modern deep learning era.
In 2016, another milestone arrived: AlphaGo, developed by Google DeepMind, defeated the world champion Lee Sedol in the ancient game of Go – a feat long thought impossible for machines. Due to its vast search space – the number of legal board positions in Go has been approximated to be around \(2.1×10^{170}\) which is far greater than the number of atoms (\(10^{80}\)) in the observable universe – and intuitive gameplay, Go was considered far too complex for AI. Unlike Deep Blue, AlphaGo used CNN and reinforcement learning with an advanced tree search algorithm.
Knowledge Search Revolution
Google, with its goal of making knowledge accessible to everyone on this planet, has so far been the best knowledge indexing system. As GPT models mature, they have begun challenging traditional search. We have sites like perplexity and chatgpt.com that can also provide a real-time search capability with the added feature of being conversational. There we have it, a chatbot, an actual thing that can talk back to humans, and not just crunch some numbers and algorithms and spit out the millions and millions of search results, for us to determine and pick the right answer to our query.
Limitations & Risks
GPT models also have some key limitations and risks worth understanding.
First is: the data being fed to the GPT models during pretraining might be wrong to begin with. Factually wrong is one, but we could have geopolitically, sociologically, and ethically wrong information being supplied. Some of the early instances of hate speech and harmful responses from these GPT models have flagged the importance of using correct training datasets.
Second is even the well-trained models can generate hallucinations and factual errors. While conversational AIs can generate one succinct answer to questions that we ask them, it does so through statistical predictions. We can split this section of limitation alone to two segments – one is directly hallucinated or factually incorrect error. Another is sometimes AI seem to make up answers where it is not sure how to answer. I will give you two examples to illustrate the later point: Sometimes, AI can start from the answer and make up the rest of the steps to get to the answers – say the answer is 1, but it could say something like 5-1 is 1, such a basic error, no school-educated human probably would make. Another is the lack of transparency behind their Chain of Thought (CoT) – Anthropic tested whether GPT models would acknowledge using hints provided in questions – even when they clearly did. They found that when you ask DeepSeek R1 or anthropic Claude 3.7 were only 39% and 25% likely respectively to admit that they used the hint to answer the question in their CoT, and the chances of them admitting that they used the hint decreased as the difficulty of the question increased.
Third is the energy consumption requirement for GPT models. OpenAI’s GPT-3 took 1.3 gigawatt-hours (GWh) – roughly the annual energy consumption of 130 average US homes – while GPT-4 took 50 GWh to train. Checkout this Business Energy UK chart for a visualized information on how energy consumption for ChatGPT. The byproduct of training these models on massive datasets using massive energy is greenhouse gas emission.
Finally, a fundamental question to the importance of work for humans – will my work be replaced by AI? Often, people derive meaning in their life through the work they do to contribute to the world. Knowledge workers – those working in field requiring a lot of writing/reading – are expected to receive the biggest task displacement impact. They include writers, marketers, programmers etc.
What’s next?
Looking at both current capabilities and limitations what does the future hold?
Agentic AI represents the next major frontier. The idea is that these GPT based AI models might at some point be able to autonomously plan and execute tasks on your behalf. Preview versions or relatively more expensive versions like OpenAI Operator, Manus AI etc. already have appeared.
As GPT models get smarter, it is expected to increase our productivity further as we expect from any novel technology. A survey, conducted by Federal Reserve at St. Louis – where respondents were asked “how much additional time they would need to complete the same amount of work last week if they had not been able to use GPT models” – found that using generative AI increased their employees’ productivity by 5%. The same study concluded that information service workers are using as well as are getting the largest productivity boost, with Manufacturing, transportation and Leisure related workers seeing the least productivity increase.
Artificial General Intelligence is supposedly the next advancement we might be looking at with these GPT-powered systems. We have Anthropic founder Dario Amodei suggesting that AGI could emerge as soon as 2026, while academic surveys including Geoffrey Hinton saying that AGI might arrive by 2040-2050 with 50% likelihood and up to 90% by 2075.
Love it or fear it, GPT has been and will continue to advance further every year. Whether this transformation proves beneficial or disruptive may depend largely on how thoughtfully we navigate the challenges ahead.